-
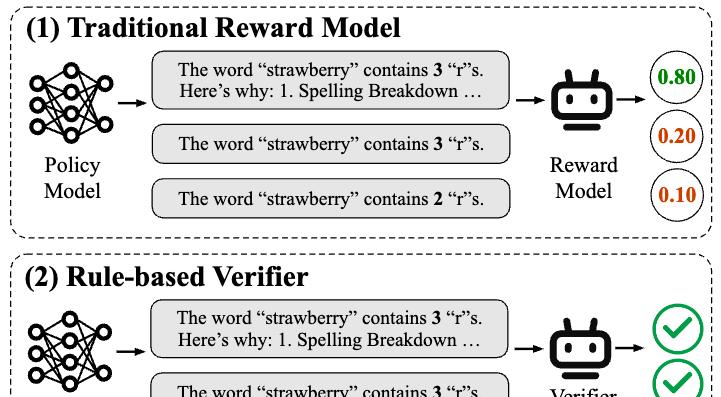
奖励模型终于迎来预训练新时代!上海AI Lab、复旦POLAR,开启Scaling新范式
在大语言模型后训练阶段,强化学习已成为提升模型能力、对齐人类偏好,并有望迈向 AGI 的核心方法。然而,奖励模型的设计与训练始终...
 游客 2025-07-15 4 0
游客 2025-07-15 4 0 -

真实科研水平集体不及格!全新基准SFE给主流多模态LLM来了波暴击
当前,驱动科学研究的人工智能(AI for Science,AI4S)在单点取得了可观的进展,实现了工具层面的革新,然而要成...
游客 2025-07-15 3 0

没有更多内容